AI-Generated Love Poetry
Posted on 2020-07-06
About a year ago, my girlfriend and I were coming up on our 2-year anniversary. I wanted to do something for her that really showed how much I cared, so I decided I would write a love poem. I spent long hours thinking and writing, churning out draft after draft of truly cringe-worthy material. Feeling somewhat embarrassed and very much defeated, I began to question my worth as a poet.
Around the same time, I had been looking into Natural Language Processing and the power of recurrent neural networks. This gave me a somewhat evil idea. What if I could harness the power of machine learning to have my computer write love poetry for my girlfriend? In this post, I will present my computer's journey from love poetry zero to hero.
Background: Recurrent Neural Networks
Human language is complicated. We have thousands of words, each made up of a different number of letters in different combinations. Sentences are filled with lexical quirks, and words can mean completely different things depending on where they are in a sentence. Even something as simple as a comma can drastically change the meaning of a sentence ("Let's eat grandma!").
To deal with all of this complexity, we can use a recurrent neural network (RNN). Andrej Karpathy does an excellent job describing these models in his blog post, The Unreasonable Effectiveness of Recurrent Neural Networks. In his blog, he shares this image:

Here, the red boxes are inputs, the green boxes are internal layers, and the blue boxes are outputs. The leftmost diagram represents a traditional neural network, where inputs of a fixed length are taken in, and an output of a fixed length is returned. This could be a model which takes in an image and returns whether the image is of a cat or a dog, or any other application. We are more interested in the rightmost diagram, as this is how our mechanical bard will end up operating. Another image from Karpathy's blog illustrates this further:
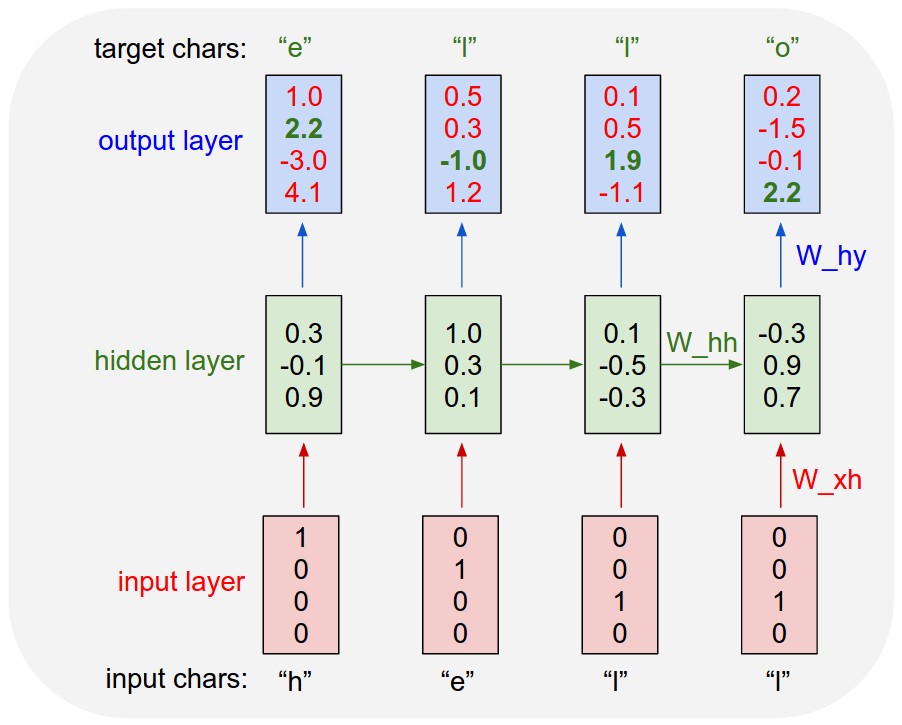
A large part of natural language processing is choosing how to translate something symbolic, like text, into something a neural network can understand. Neural networks are great with vectors and matrices, so we have to try to get our text into that format. The trick is to "tokenize" the text, breaking it up into uniform components. These components, or tokens, can be anything from individual letters to entire words. We define a dictionary of possible tokens, like the 1000 most common English words or the letters in the alphabet. Then we assign each token a number, so maybe "a" is 0, "b" is 1, etc. Lastly, we create a vector for each token, where the value at the index of a given token is 1, and the rest are zeros. For example, you could represent all the lower-case letters as a vector of length 26. Then, (1,0,0,...,0) would correspond to "a", (0,1,...,0) would correspond to "b", and so on. This technique is known as one-hot encoding.
One advantage to this strategy is that we can think of the elements in the vector as probabilities of a given token occurring. When encoding a letter, the 1 at its index means that there's a 100% chance of the vector representing that letter. When we feed a vector into our neural network, it will output another vector of the same length, representing what the network thinks the next token in the sequence will be. Additionally, it will output some hidden state, which is passed along to the next iteration when the model guesses the next token. The model can then see how far off its predictions were and adjust accordingly, effectively learning the structure of whatever input it's given.
Constructing the Dataset
A machine learning model can only be as good as the data it's trained on. In our case, this means finding as much love poetry as possible. Unfortunately, no single repository of love poetry currently exists. Luckily, however, there are plenty of websites with collections of wonderful poems. Most of these sites share a common design, with a landing page linking to several individual poems. An example of one of these websites can be found here. I decided to split my data gathering into three separate stages: a crawler, a scraper, and a constructor. Each stage had its own function, and the modularity allowed me to adapt each component as necessary to account for the variation of layouts on different pages. Below, I will walk through each of these sections, applied to https://theromantic.com/love_poems/main.htm
Crawler
The job of the crawler was to extract all of the links to all of the poems on
a given site. To do this, I used the
BeautifulSoup
Python library, which is useful for parsing the HTML of a webpage. The code can
be seen below. We first make sure our save directory exists, then use the
requests and BeautifulSoup libraries to get and parse the HTML of the site.
We can then get all the links and filter out the invalid ones. Lastly, we write
the output to a text file and save it. The entire code can be seen below.
from bs4 import BeautifulSoup
import requests, os, time, re
#setup directory
initial_page = 'https://theromantic.com/love_poems/main.htm'
dir = 'Text/'
os.makedirs('Text',exist_ok=True)
#filter site for all links
def link_getter():
links = []
for a in soup.find_all('a', href=True):
links.append(a['href'])
return(links)
#checks if item is valid
def valid(item):
if 'http://theromantic.com/love_poems/' in str(item):
return True
else:
return False
#gather website html
res = requests.get(initial_page)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'lxml')
#find all links and filter out desired ones
linkElem = link_getter()
filtered = filter(valid,linkElem)
#dump links in a file
with open(dir+'links.txt','w') as f:
for addr in filtered:
f.write(addr+'\n')Scraper
Once a list of the individual pages has been generated, the next step in the process is to visit each site and parse the love poem in question. Each website has a bit different formatting, so I modified the code as I went. However, the basic steps required remained the same. First, we create the output folder and read the input links from the text file. These links can then be iterated over and their contents extracted. The resulting lines of text can all be written to one large text file, which can later be processed by the machine learning model.
The only part that really differs between sites is extracting the poem text from the HTML. This process first involved figuring out which tags contained the poem, and then using regular expressions to strip away any extra HTML tags and artifacts, leaving us with one clean text file. The code for doing this for https://theromantic.com/love_poems/main.htm' can be seen below.
from bs4 import BeautifulSoup
import requests, os, time, re
#initial setup
dir = 'Text/theromantic/'
os.makedirs(dir, exist_ok = True)
#read file for links and clean them up
link_dir = 'Text/links.txt'
with open(link_dir,'r') as f:
links = f.readlines()
links = [i.strip() for i in links]
#extracts the text
def extract_text(soup):
h3 = soup.findAll('h3')
h3 = h3[0]
title = re.sub('<[^>]*>','',str(h3))
poem = []
p = h3.find_next_sibling()
while '<div' not in str(p):
if '<p>' in str(p):
poem.append(p)
p = p.find_next_sibling()
text = title + '\n'
for i,item in enumerate(poem):
item = str(item)
item = item.replace('<br/>','\n')
item = item.replace('</p>','\n')
item = re.sub('<[^>]*>','',item)
text += item + '\n'
return text
#gathering the data
data = []
for i,link in enumerate(links):
print(i)
res = requests.get(link)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'lxml')
data.append(extract_text(soup))
#writing the data to files
for item in data:
filename = dir + re.sub(r'\W+','',item)[:10] + '.txt'
with open(filename,'w') as f:
f.write(item)Constructor
This last stage is probably the easiest. All we are doing here is combining
the text from all the different files we generated into one large file.
This makes it much easier to train the model, since we will only have to
open one text file and extract the text. I used the
glob
Python library to easily gather the files. This library is nice because it
lets you use UNIX-style path expansions inside of Python. The code here is
fairly simple. It just involves using glob to get a list of all the text
files, concatenating all of their data together, and saving it all to one
giant text file. The only somewhat strange thing I did here was to use a
\s character to act as the end of a poem, so that the model could learn
to create a fully formed poem, and not just ramble on forever. The code for
this can be seen below.
from glob import glob
files = glob('./Text/**/*.txt',recursive=True)
files = [i for i in files if ('links.txt' not in i and 'poetry.txt' not in i)]
data = []
for file in files:
with open(file,'r') as f:
data.append(f.read())
with open('./Poet/poetry.txt','w') as f:
for item in data:
item = item.replace('We have the best collection of love poems on the web. Click here for more love poems on our site','')
f.write(item)
f.write('\s')Model Construction and Training
In constructing my model, I utilized this blogpost by Yash Nagda as a reference. The post was very insightful, and taught me a lot about how to implement an RNN in Pytorch. Specifically, we will be making a Character RNN, which predicts the next character (letter, space, etc.) at any given step. This approach is interesting because we will be able to see the model learn English all on its own, and hopefully compose a coherent poem.
The first step, after importing libraries, is to read in our text and create the encoding scheme. The code below walks through that process.
#import text
with open('poetry.txt','r',encoding='cp1252') as f:
text = f.read()
# encoding the text and map each character to an integer and vice versa
# 1. int2char, which maps integers to characters
# 2. char2int, which maps characters to integers
chars = tuple(set(text))
int2char = dict(enumerate(chars))
char2int = {ch:ii for ii,ch in int2char.items()}
encoded = np.array([char2int[i] for i in text])We can then define our network. We will use an LSTM for the hidden layer, which is fairly similar to a standard RNN, but contains memory cells which can remember information from previous runs ad helps make the model more powerful. You can read more about LSTMs here.
# Declaring the model
class CharRNN(nn.Module):
def __init__(self, tokens, n_hidden=256, n_layers=2,drop_prob=0.5, lr=0.001):
super().__init__()
self.drop_prob = drop_prob
self.n_layers = n_layers
self.n_hidden = n_hidden
self.lr = lr
self.train_on_gpu = torch.cuda.is_available()
# creating character dictionaries
self.chars = tokens
self.int2char = dict(enumerate(self.chars))
self.char2int = {ch: ii for ii, ch in self.int2char.items()}
#define the LSTM
self.lstm = nn.LSTM(len(self.chars), n_hidden, n_layers,
dropout=drop_prob, batch_first=True)
#define a dropout layer
self.dropout = nn.Dropout(drop_prob)
#define the final, fully-connected output layer
self.fc = nn.Linear(n_hidden, len(self.chars))
def forward(self, x, hidden):
''' Forward pass through the network.
These inputs are x, and the hidden/cell state `hidden`. '''
#get the outputs and the new hidden state from the lstm
r_output, hidden = self.lstm(x, hidden)
#pass through a dropout layer
out = self.dropout(r_output)
# Stack up LSTM outputs using view
out = out.contiguous().view(-1, self.n_hidden)
#put x through the fully-connected layer
out = self.fc(out)
# return the final output and the hidden state
return out, hidden
def init_hidden(self, batch_size):
''' Initializes hidden state '''
# Create two new tensors with sizes n_layers x batch_size x n_hidden,
# initialized to zero, for hidden state and cell state of LSTM
weight = next(self.parameters()).data
if (self.train_on_gpu):
hidden = (weight.new(self.n_layers, batch_size, self.n_hidden).zero_().cuda(),
weight.new(self.n_layers, batch_size, self.n_hidden).zero_().cuda())
else:
hidden = (weight.new(self.n_layers, batch_size, self.n_hidden).zero_(),
weight.new(self.n_layers, batch_size, self.n_hidden).zero_())
return hiddenFinally, we define our training function. This function will take in our model
and train it on our corpus of data. It is a fairly standard training function,
using Adam as an optimizer. After fiddling with the parameters a bit, I ended
up training my model for 100 epochs with a learning rate of .001.
# Declaring the train method
def train(net, data, train_on_gpu, epochs=10, batch_size=10, seq_length=50, lr=0.001, clip=5, val_frac=0.1, print_every=10):
net.train()
opt = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
# create training and validation data
#split according to val_frac arg
val_idx = int(len(data)*(1-val_frac))
data, val_data = data[:val_idx], data[val_idx:]
if(train_on_gpu):
net.cuda()
counter = 0
n_chars = len(net.chars)
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
for x, y in get_batches(data, batch_size, seq_length):
#x shape: batch_sizexseq_length-128x100
counter += 1
# One-hot encode our data and make them Torch tensors
x = one_hot_encode(x, n_chars)
inputs, targets = torch.from_numpy(x), torch.from_numpy(y)
if train_on_gpu:
inputs, targets = inputs.cuda(), targets.cuda()
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
h = tuple([each.data for each in h])
# zero accumulated gradients
net.zero_grad()
# get the output from the model
output, h = net(inputs, h)
# calculate the loss and perform backprop
loss = criterion(output, targets.view(batch_size*seq_length).long())
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
nn.utils.clip_grad_norm_(net.parameters(), clip)
opt.step()
# loss stats
if counter % print_every == 0:
# Get validation loss
val_h = net.init_hidden(batch_size)
val_losses = []
net.eval()
for x, y in get_batches(val_data, batch_size, seq_length):
# One-hot encode our data and make them Torch tensors
x = one_hot_encode(x, n_chars)
x, y = torch.from_numpy(x), torch.from_numpy(y)
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
val_h = tuple([each.data for each in val_h])
inputs, targets = x, y
if(train_on_gpu):
inputs, targets = inputs.cuda(), targets.cuda()
output, val_h = net(inputs, val_h)
val_loss = criterion(output, targets.view(batch_size*seq_length).long())
val_losses.append(val_loss.item())
net.train() # reset to train mode after iterationg through validation data
print("Epoch: {}/{}...".format(e+1, epochs),
"Step: {}...".format(counter),
"Loss: {:.4f}...".format(loss.item()),
"Val Loss: {:.4f}".format(np.mean(val_losses)))
torch.save(net.state_dict(),'weights.ckpt')Results and Takeaways
After training my model, the next part of the process was to get it to write me some love poetry. To do this, I would "seed" the model by giving it a word to start with, say "The", and letting it come up with the next bits of text all on its own. This would be a bit like starting a text on your phone, and then letting your word predictor finish the text for you.
In order to get new text from the model, we first feed it a short priming message. The output from feeding in each letter will be a vector, with different values between 0 and 1. We interpret these values as being the probabilities of the next letter having a certain value, and randomly choose the next letter based on these probabilities. This way, our text will have the desired structure of the network, but won't be too deterministic and boring. The code to accomplish all of this can be found below.
net = CharRNN(chars, n_hidden, n_layers)
net.load_state_dict(torch.load('weights.ckpt'))
print(net)
# Declaring the hyperparameters
batch_size = 128
seq_length = 100
# Defining a method to generate the next character
def predict(net, char, h=None, top_k=None):
''' Given a character, predict the next character.
Returns the predicted character and the hidden state.
'''
# tensor inputs
x = np.array([[net.char2int[char]]])
x = one_hot_encode(x, len(net.chars))
inputs = torch.from_numpy(x)
if(train_on_gpu):
inputs = inputs.cuda()
# detach hidden state from history
h = tuple([each.data for each in h])
# get the output of the model
out, h = net(inputs, h)
# get the character probabilities
p = F.softmax(out, dim=1).data
if(train_on_gpu):
p = p.cpu() # move to cpu
# get top characters
if top_k is None:
top_ch = np.arange(len(net.chars))
else:
p, top_ch = p.topk(top_k)
top_ch = top_ch.numpy().squeeze()
# select the likely next character with some element of randomness
p = p.numpy().squeeze()
char = np.random.choice(top_ch, p=p/p.sum())
# return the encoded value of the predicted char and the hidden state
return net.int2char[char], h
def sample(net, size, prime='The', top_k=None):
if(train_on_gpu):
net.cuda()
else:
net.cpu()
net.eval() # eval mode
# First off, run through the prime characters
chars = [ch for ch in prime]
h = net.init_hidden(1)
for ch in prime:
char, h = predict(net, ch, h, top_k=top_k)
chars.append(char)
# Now pass in the previous character and get a new one
for ii in range(size):
char, h = predict(net, chars[-1], h, top_k=top_k)
chars.append(char)
return ''.join(chars)
# Generating new text
print(sample(net, 1000, prime='The', top_k=5))
with open('New_Poetry.txt','w') as f:
poetry = sample(net, 10000, prime='The', top_k=5)The results from this process were... interesting. Overall, I was very impressed by the model's ability to learn English, and even come up with some (seemingly) profound and beautiful poetry. When creating my final poetry, I decided to run everything through a spell checker, which I figured was still within the bounds of an automated solution. Here are some sample poems:
As Long As You're Near
The first time we met, I could see,
That you and I, with my shile
A dreams that one way someone
With you as that I could not faily
I'll kiss the search escanes that we share.
You are the sun rises above the hillcriogs
And hearts will be three first tomorrow
I looked into your eyes
I'll fly with you at my hind
You're my darling my tonce
The chide of sun roses,
And missen of all ores
Which you are surringed,
It makes me so happyAs you can see from this output, our poet has some interesting taste in poetry. Sometimes, it invents new words like "shile", and other times plagiarizes entire lines from poetry it's seen before. One of the hardest parts of creating this kind of model is balancing overfitting and underfitting. In this context, overfitting would be the model not producing any original output, and instead just parroting training data again and again. Underfitting would be the model not fully learning what it intended, and having a half-baked understanding of English. If I were to spend more time with this project, my effort would mostly go towards limiting these two errors. The model already employs Dropout, but exploring other regularization techniques could help keep our robotic poet from stealing its lines.
In all, this project was a lot of fun. It taught me about the fine art of web scraping, the fickle beasts of Recurrent Neural Networks, and showed me that the future of creativity might just be robotic. All of the code from this blog can be found here. Thanks for reading!